PLY
The asteroid to kill this dinosaur is still in orbit.
PLY o python-ply (cómo se llama su paquete en Debian) es una implementación de las herramientas lex y yacc para análisis léxico y sintáctico. Está enteramente escrito en Python y su primera versión fue desarrollado por David Beazley en el año 2001 para ser usado en un curso de Introducción a los Compiladores.
Lex
Lex es una creador de analizadores léxicos (lexers). La función principal de un lexer es tomar un flujo de caracteres entrada y devolver un flujo de tokens como salida. Ejemplos de tokens en un programa escrito en algún lenguaje de programación podrían ser: un número, un paréntesis, un identificador o una palabra clave. Por ejemplo: 17, ), miVarible, if.
Para definir los tokens utilizamos expresiones regulares.
Yacc
Yacc, Yet Another Compilers Compiler, nos permitirá crear un programa que tome un flujo de tokens como entrada y reconozca a partir de ellos un lenguaje. Notemos por ejemplo que si bien if { 555 ;; for printf i++[] es un flujo de tokens válidos de C, no es una sentencia válida del lenguaje como si lo es for(i=0; i<5; i++){}.
Para definir la gramática de un lenguaje de programación vamos a usar una notación conocida como BNF (Backus–Naur form).
MiniLisp
Intérpretes de lenguajes de programación como Python o PHP son escritos en C por razones de eficiencia. ¿Vamos a usar Python para escribir uno? Bueno.. ¿por qué no? La filosofía de Python consiste en escribir rápido una solución para un problema y poder probarla enseguida. En el tiempo en que implementás en C una idea podes escribir 3 soluciones diferentes en Python, probarlas y elegir con cual continuar. En caso de que en algún momento se detecte que el programa resultante corre lento (más lento de lo necesario), siempre podés:
- realizar optimizaciones en el código Python
- reescribir en C alguna parte critica del mismo.
El intérprete que voy a construir para aprender ply va a tener sabor a Lisp y va a ser muy sencillo. Va a ser un MiniLisp! En particular:
- Usará notación prefija mediante paréntesis de la forma
(fun-name arg [arg]). Esto significa que el intérprete podrá resolver expresiones como (+ 1 1) y responderá 2, (= 1 1) y responderá #t (la forma en que voy a representar el valor de verdad True), pero también (+ 1 2 3 4 5) que da como resultado 15 y (or #t #f #f) que da como resultado #t.
- Permitirá resolver expresiones anidadas. Esto significa que además de las expresiones anteriores, podrá resolver expresiones como
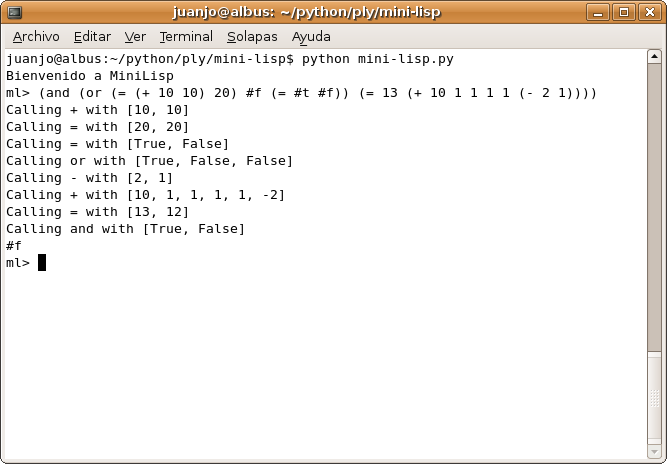
(+ 1 (+ 2 2) (- 5 4) 10) que da como resultado 16, (and (= 1 1) #t) que da como resultado #t y (and (or (= (+ 10 10) 20) #f (= #t #f)) (= 13 (+ 10 1 1 1 1 (- 2 1)))) cuyo resultado se deja a cargo del lector para que vaya entrando en clima :)
- Contará con funciones de manejo de listas típicas en Lisp como car, cdr y cons:
-
(car '(1 2 3)) obtiene el primer elemento (o cabeza) de la lista '(1 2 3): 1
-
(cdr '(1 2 3)) obtiene la cola de la lista '(1 2 3): (2 3)
-
(cons 0 '(1 2 3)) crea una nueva lista con 0 como cabeza y '(1 2 3) como cola: (0 1 2 3)
- Notar que
(cons '(1 2) '(3 4)) da como resultado una lista cuya cabeza es la lista '(1 2) y su cola '(3 4): ((1 2) 3 4)
- También se podrá usar
(concat '(1 2) '(3 4)) para obtener una lista que sea la concatenación de ambas: (1 2 3 4)
- y
(list 1 2 3 4) para crear una lista de elementos: (1 2 3 4)
<li>La implementación tiene solo fines didácticos así que solo trabajará con enteros aunque añadir soporte para números reales (floats) debería ser fácil.</li>
<li>No tendrá un manejo de errores muy completo.</li>
<li>Pensé varias formas de implementar la función <code>define</code> pero no conseguí que funcione del todo bien :(, así que quité la funcionalidad.</li>
<li>Otra función común en las implementaciones de Lisp con la que contará MiniLisp es cond, la cual evalúa su primer argumento y si es verdadero retorna el segundo. Esta función puede usarse para implementar construcciones de control de flujo más complejas como if-else, while o for. Eso si en MiniLisp se pudieran definir funciones :(
-
(cond (= 1 1) 7) retorna 7
- pero
(cond (= 1 2) 7) no retorna nada.
Manos a la obra
PLY consiste en un paquete que contiene los módulos ply y yacc.
En Debian/Ubuntu podemos instalarlo con el comando (como root o mediante sudo)
apt-get install python-ply
lex.py
Al programa que generará un analizador léxico lo llamé lex.py y consiste en:
import ply.lex as lex
Debemos crear una tupla con todos los nombres de los tokens a reconocer (por convención escribimos los nombres en mayúsculas):
tokens = ('QUOTE', 'SIMB', 'NUM', 'LPAREN', 'RPAREN', 'NIL', 'TRUE', 'FALSE', 'TEXT')
Un diccionario en el cual la clave es una palabra reservada y el valor uno de los tokens de la tupla anterior:
reserved = {
'nil' : 'NIL',
}
En este ejemplo prácticamente no hay palabras reservadas, otros lenguajes podría haber palabras como if, while, for o return.
Lo siguiente es definir las expresiones regulares para cada token. Existen dos formas de hacerlo, mediante strings o mediante funciones.
El primer caso se usa cuando el token no requiere ningún tipo de procesamiento luego de ser econtrado:
t_LPAREN = r'\('
t_RPAREN = r'\)'
t_QUOTE = r'\''
t_TRUE = r'\#t'
t_FALSE = r'\#f'
Notar que se usan raw strings de Python para escribir las expresiones regulares que posteriormente serán compiladas y usadas (PLY utiliza el módulo re en su análisis léxico).
Para los tokens correspondientes a números podemos querer hacer alguna verificación antes de devolverlo, en ese caso la especificación del token puede hacerse mediante una función:
def t_NUM(t):
r'd+'
try:
t.value = int(t.value)
except ValueError:
print "Line %d: Number %s is too large!" % (t.lineno,t.value)
t.value = 0
return t
Notar que en el docstring de la función se debe colocar la expresión regular correspondiente al token.
Otro ejemplo de esto se da para el token SIMBOL, pero con una particularidad. Este token se usa para los nombres de funciones o variables. car, cdr o and son ejemplos de símbolos en MiniLisp.
def t_SIMB(t):
r'[a-zA-Z_+=*-][a-zA-Z0-9_+*-]*'
t.type = reserved.get(t.value,'SIMB') # Check for reserved words
return t
Luego de encontrar una secuencia de caracteres que corresponda con la expresión regular de los símbolos, nos fijamos que no sea una palabra reservada. Si lo es, en t.type se guardará el nombre de token correspondiente, por ejemplo 'NIL', caso contrario 'SIMB'.
Si hubiesemos especificado t_NIL = r'nil' en lugar de usar el diccionario reserved, cadenas de caracteres como nillave (un símbolo válido) serían interpretadas como NIL seguido del símbolo lave.
El orden en que estas definiciones son usadas es el siguiente: primero los strings en orden descendiente de la longitud de la expresión regular y luego las funciones en el orden que fueron escritas.
Archivo completo: lex.py
yacc.py
El código en el que se define la gramática del lenguaje lo puse en un archivo llamado yacc.py. El siguiente BNF expresa la gramática de MiniLisp (las palabras en mayúsculas representan símbolos terminales y las palabras en minúsculas símbolos no terminales), a la izquierda de la regla siempre va un único elemento y el símbolo ::= puede leer se como 'es':
exp ::= atom
exp ::= quoted_list
exp ::= call
quoted_list ::= QUOTE list
list ::= LPAREN items RPAREN
items ::= item items
items ::=
item ::= atom
item ::= list
item ::= quoted_list
item ::= call
call ::= LPAREN SIMB items RPAREN
atom ::= SIMB
atom ::= bool
atom ::= NUM
atom ::= TEXT
atom ::=
bool ::= TRUE
bool ::= FALSE
atom ::= NIL
y lo siguiente es cómo queda la gramática expresa en código. Se debe definir una función por cada una de las reglas previas (el docstring de la función corresponde a la regla). Cada función recibe como parámetro un objeto iterable (muy parecido a una lista, pero que no se comporta totalmente como tal, así que cuidado con los subíndices negativos) que contiene los valores de cada símbolo de la regla.
# BNF
def p_exp_atom(p):
'exp : atom'
p[0] = p[1]
def p_exp_qlist(p):
'exp : quoted_list'
p[0] = p[1]
def p_exp_call(p):
'exp : call'
p[0] = p[1]
def p_quoted_list(p):
'quoted_list : QUOTE list'
p[0] = p[2]
def p_list(p):
'list : LPAREN items RPAREN'
p[0] = p[2]
f = p[2][0]
def p_items(p):
'items : item items'
p[0] = [p[1]] + p[2]
def p_items_empty(p):
'items : empty'
p[0] = []
def p_empty(p):
'empty :'
pass
def p_item_atom(p):
'item : atom'
p[0] = p[1]
def p_item_list(p):
'item : list'
p[0] = p[1]
def p_item_list(p):
'item : quoted_list'
p[0] = p[1]
def p_item_call(p):
'item : call'
p[0] = p[1]
def p_call(p):
'call : LPAREN SIMB items RPAREN'
if DEBUG: print "Calling", p[2], "with", p[3]
p[0] = lisp_eval(p[2], p[3])
def p_atom_simbol(p):
'atom : SIMB'
p[0] = p[1]
def p_atom_bool(p):
'atom : bool'
p[0] = p[1]
def p_atom_num(p):
'atom : NUM'
p[0] = p[1]
def p_atom_word(p):
'atom : TEXT'
p[0] = p[1]
def p_atom_empty(p):
'atom :'
pass
def p_true(p):
'bool : TRUE'
p[0] = True
def p_false(p):
'bool : FALSE'
p[0] = False
def p_nil(p):
'atom : NIL'
p[0] = None
En yacc.py pueden verse todos los detalles de implementación que logran hacer que esta estructura arbórea que podemos armar con yacc pueda manipularse para trabajar como un intérprete de Lisp. La implementación concreta fue hecha mediante funciones sencillas escritas en Python. Traté de mantener el engine del lenguaje lo más simple posible ya que el objetivo principal fue trabajar en el analizador léxico/sintáctico del mismo.
En particular destaco el uso de las listas de Python (una estructura de datos muy poderosa) como componente fundamental de este pequeño Lisp.
mini-lisp.py
Finalmente utilicé el módulo cmd (parte de la librería estándar de Python) para crear la interfaz de línea de comandos del intérprete:
# -*- coding: utf-8 -*-
from yacc import yacc, lisp_str
import cmd
class MiniLisp(cmd.Cmd):
"""
MiniLisp evalúa expresiones sencillas con sabor a lisp,
más información en https://viejoblog.juanjoconti.com.ar
"""
def __init__(self):
cmd.Cmd.__init__(self)
self.prompt = "ml> "
self.intro = "Bienvenido a MiniLisp"
def do_exit(self, args):
"""Exits from the console"""
return -1
def do_EOF(self, args):
"""Exit on system end of file character"""
print "Good bye!"
return self.do_exit(args)
def do_help(self, args):
print self.__doc__
def emptyline(self):
"""Do nothing on empty input line"""
pass
def default(self, line):
"""Called on an input line when the command prefix
is not recognized.
In that case we execute the line as Python code.
"""
result = yacc.parse(line)
s = lisp_str(result)
if s != 'nil':
print s
if __name__ == '__main__':
ml = MiniLisp()
ml.cmdloop()
Con esto se logra tener algunas funcionalidades útiles como poder usar las flechas izquierda y derecha del teclado para movernos por la línea que estamos escribiendo y las flechas arriba y abajo para movernos por la historia de las expresiones que fuimos introduciendo.
Resultado
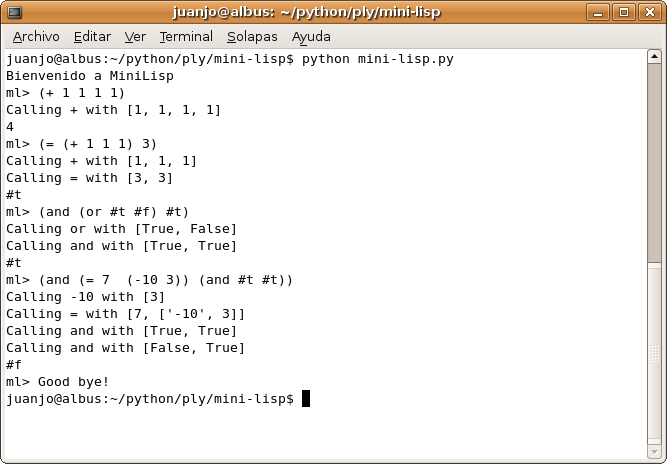
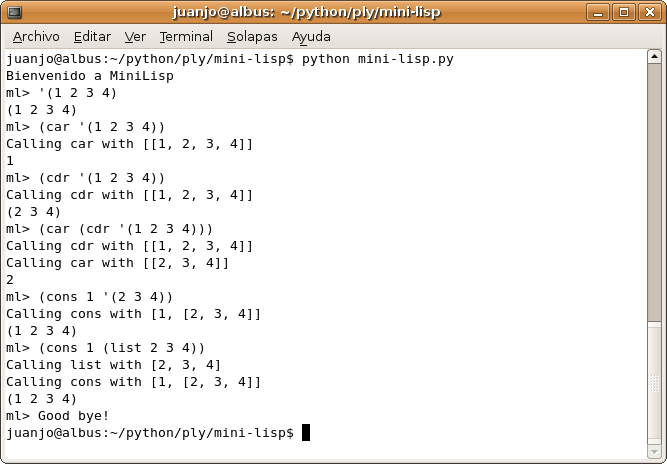
En las siguientes capturas de pantalla se ven ejemplos de MiniLisp en acción:
Operaciones básicas
Manejo de listas
Ejercicio planteado al lector
El código fuente completo de MiniLisp está empaquetado en: mini-lisp-0.1.tgz
También puede navegarse en: https://viejoblog.juanjoconti.com.ar/files/python/mini-lisp/
Conclusión
Si bien la implementación lograda dista mucho (en su funcionalidad) de una implementación real de Lisp, su sintaxis (aunque simple como la del propio Lisp) es lo que quería lograr y me sirvió para hacer muchas pruebas (algunos de sus resultados son reflejados en este artículo).
El objetivo de este desarrollo fue aprender PLY para poder utilizarlo en un proyecto que si bien no es un lenguaje de programación, se le parece en la necesidad de realizar un análisis léxico/sintáctico: un probador de teoremas (ATP).
Referencias
Desde el sitio web de ply se puede acceder a su documentación.
Sobre compiladores: Compiladores: técnicas, principios y herramientas.
Update: unas palabras sobre reducción
Supongamos que la expresión que se analizará sintácticamente (ya pasó por el analizador léxico, es decir que consiste de tokens válidos) es: (= (+ 1 1) 2).
En base a las reglas BNF definidas, esta expresión puede verse como el siguiente árbol:

La expresión se va resolviendo de abajo hacia arriba en el árbol (o lo que es lo mismo de adentro hacia afuera en la expresión) mediante la aplicación de las funciones definidas.
 Download: cecilia_music_game-1.0
Download: cecilia_music_game-1.0