Estoy haciendo un juego inspirado en el Juego de la Vida. A modo de bonus-track también se podrán ver algunos patrones del tradicional juego de cero jugadores. Algunos patrones se cargarán de archivos en la computadora y se pondrán a disposición de usuario para que los examine. Para una mayor comodidad va a haber un botón "atrás" (>).
Si lo anterior fuera un enunciado en un examen de Algoritmos y Estructuras de Datos, ¿cual sería la estructura de datos más adecuada para mantener esa información? Sin dudas una lista circular. No sería muy agradable llegar al último patrón, apreatar "siguiente" y que no pase nada. Quiere que cuando esté parado en el último elemento y apriete "siguiente", me muestre el primero.
Una lista circular es una lista lineal en la que el último nodo a punta al primero.
Las listas circulares evitan excepciones en la operaciones que se realicen sobre ellas. No existen casos especiales, cada nodo siempre tiene uno anterior y uno siguiente.
El artículo va a ser un poco largo, va apasar por algunos lenguajes de programación y va a evaluar distintos enfoques. Pero adelanto que va a terminar en una implementación de una lista circular en Python basada en el manejo de índice.
Enfoque C
Conocí este tipo de estructura en la materia que mensioné más arriba. Usabamos C como lenguaje de programación, así que fué el primer lenguaje dónde implementé una. A esta estructura de datos se la llama dinámica por que puede crecer indefinidamente alocando porciones de memoria de la computadora, sin necesidad de que estas estén físicamente contiguas.
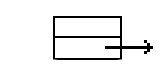
Supongamos que la lista circular va a ser de enteros (por simplicidad). Se necesitarán 1) una estructura Nodo más o menos así:
typedef struct nodo {
int dato;
struct nodo *next;
} nodo;
o así:
typedef struct nodo {
int dato;
struct nodo *next;
struct nodo * prev;
} nodo;
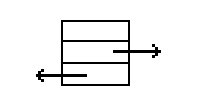
Las flechas de los dibujos son punteros (direcciones en memoria) a otros nodos, mediante los cuales estos se van a ir uniendo, bien para formar una lista lineal o para formar una lista como las que nos interesan, cuando el último nodo con su puntero next apunte al primero.
2) una forma de solicitar memoria para un nuevo nodo:
nodo * pnodo = (nodo *)malloc(sizeof(nodo));
y 3) manejar punteros; un puntero a la lista, uno a la posición actual, uno a la anterior a la actual.
Si bien usar estos elementos de la forma correcta is not rocket science, requiere cierto conocimiento de un nivel más bajo (por más cercano al hardware) de lo que los modernos lenguajes dinámicos nos tiene acostumbrado (de hecho en los lenguajes de más alto nivel, este problema ya viene solucionado).
Para solucionar mi problema voy a preferir una solución con un poquito más de nivel de abstracción, pero creo que este enfoque a modo de introducción sirve para ir poniendo las piezas en el tablero.
Enfoque Haskell
En la pasada CafeConf fuí a una charla de mi amigo Pupeno sobre lenguajes de programación, allí vi algo que no conocía. En Haskell, nos mostro este concepto: Listas infinitas. Lenguajes como este tiene una propiedad llamada Lazyness
En programación, lazy evaluation, también llamada delayed evaluation, es la técnica que consiste en retrasar un cálculo computacional hasta el momento en que su resultado se necesite.
Por ejemplo:
x = calculo_intensivo(1000)
no necesita ser evaluado hasta que por ejemplo se haga:
print x + 1
Esta propiedad permite entre otras cosas crear listas infinitas (de nuevo un un pseudo código muy parecido a Python):
miListaInfinita = ListaInfinita(arg)
Claro que no vamos a poder hacer:
print miListaInfinita
O podríamos pero la operación no terminaría nunca, pero si prodríamos hacer:
print miListaInfinita[100004]
Y dependiendo de la clase de lista infinita que sea se necesitarán calcular los anteriores términos (en el caso de por ejemplo la lista de Fibonacci) o no (en una lista de todos 0).
Bien. A dónde estamos yendo con todo esto? Al fin de cuentas yo estaba buscando una lista circular y me encontré con listas infinitas. La conclusión es que una lista circular puede verse como una lista infinita ya que:
a) Siempre puedo pedirle un elemento siguiente sin que se agoten.
b) Puedo pedir el elemento 100004º y también obtenerlo (luego de algunas vueltas, por su puesto).
Así sería una lista crcular (infinita) en Haskell:
cycle [1,2,3]
o
a = [1,2,3|a]
Bien, puedo hacer esto en Python? Con poco esfuerzo, con mis conocimientos y en una tade de lluvia, yo no. Salvo en algunas excepciones, la evaluación en Python no es Lazy, sino Eager o estricta. De todas formas algunos links por si alguien quiere seguir investigado en esa línea:
<li>Generator expressions</li>
<ul>
<li><a href="http://gnosis.cx/publish/programming/charming_python_b13.html">http://gnosis.cx/publish/programming/charming_python_b13.html</a></li>
<li><a href="http://www.python.org/dev/peps/pep-0289/">http://www.python.org/dev/peps/pep-0289/</a></li>
<li><a href="http://docs.python.org/ref/genexpr.html">http://docs.python.org/ref/genexpr.html</a></li>
</ul>
Juanjo-ar-stafe> is python lazy?
Habbie> python allows programmers to be lazy
Habbie> and that's what matters
itchi> Juanjo-ar-stafe: Are you not lazy?? :-)
Ya que agoté esta rama, backtracking y adelante!
De todas formas esto se trataba de Python, no?
Yo estaba cometiendo el error en pensar en el término Lista circular doblemente enlazada, lo cual tiene sentido en C, pero no en Python. Yo no se como están implementadas las estrcturas de datos que provee el lenguaje y sin embargo puedo usarlas sin problemas. La diferencia en que la lista en cuestión sea doble o simplemente enlazada es solo una cuestión de optimización y no de funcionalidad. Cito una parte de uno de los mails que intercambiamos con Pupeno al respecto y que me ayudó mucho a encarar mejor el problema:
El hacer una lista doblemente enlazada nos permite agregar funciones sobre la lista que la simplemente no nos permite y/o hacer que ciertas funciones sean mas rapido.
En una lista podes hacer l.next() y tambien podes hacer l.prev() la diferencia es que prev() en una lista doblemente enlazada es constante en el tiempo O(1) y en una simple seria O(n) donde n es la cantidad de items en la lista (probablemente tenga un promedio de O(n/2)).
Ahora, me parece que lo que vos necesitas realmente es que sea circular, no es cierto?
Ahora que ya se lo que necesito, puedo poner manos a la obra. ¿Qué necesito? Un objeto que sea una secuencia mutable de elementos al que siempre que quiera pueda decirle next() o prev() y me de el elemento siguiente o anterior al actual.
Lo primero en lo que podría pensar es en crear objetos Nodo y hacer una implementación C-like, usando referencias a objetos en lugar de punteros a estructuras pero.. creo que esto sería:
a) relativamente complicado, casi tanto como sería hacerlo en C. Más si mis objetivos de eficiencia, robustez y usabilidad son altos.
y b) un desapovechamiento de lo que ya está hecho (si llegó hasta aca, por favor siga leyendo).
Una de las estructuras de datos más poderosas que vienen con Python es list, algunos ejemplos rápidos:
>>> li = [1, "hola", 5, 8.5]
>>> li[3]
8.5
>>> li[:3]
[1, 'hola', 5]
>>> li[:]
[1, 'hola', 5, 8.5]
>>> li[-2]
5
>>> li[-2:]
[5, 8.5]
>>> li + ["muy bien"]
[1, 'hola', 5, 8.5, 'muy bien']
Robusta, eficiente y muy usable.
Como pueden ver el manejo de índices le da mucha flexibilidad y es uno de los elementos más usados que constituyen el lenguaje. ¿Cuanto tiempo me tomaría hacer una implementación desde cero así solo por encapricharme con usar referencia circular? Paso.. voy a extender list y a agregar la funcionalidad que requiero mediante el manejo de índices.
Primer implementación
Esta fue la priemr implementación que hice: circular.py
Enseguida mandé un mail a mi lista preferida de Python para pedir opiniones, de seguro tenía muchas cosas por mejorar.
Review 1
Enseguida Manuel Quiñones me mandó algunas optimizaciones (antes hacía llamadas recursivas de los métodos) + pruebas hechas con DocTest: circularDocTest.py
Mezclé sus optimizaciones con mi código original (seguí sin usar una forma automatizada de testeo) para seguir discutiendo en base a este: circular-r1.py
Review 2
Lucio Torre me apuntó este comportamiento no previsto:
>> Circular([]).prev() == Circular([None]).prev()
True
Estaba retornando None cuando se solicitaba un elemento de una lista vacía. Decidí que sería mejor lanzar una excepción en ese caso: circular-r2.py
Review 3
John Lenton se tomó el trabajo de reescribir la clase en una foma mucho más compacta (gacias!). Yo estaba considerando como especiales casos que en realidad no lo eran. Además me mostró como usar test de unidad en Python, cosa que nunca había hecho: circular-r3Tested.py
Review 4
Luego de unas sugerencias de estilo decidí hacer un mejor uso de los nombres de las variables (y métodos). También agregué una sugerencia muy interesante de Gabriel Genellina, en lugar de hacer:
if self == []:
para saber si la lista está vacía, usar:
if not self:
que es más rápido.
También permito que se contruya lal ista circular sin parámetros (lo que da una list circular vacía): circular-r4Tested.py
Review 5
Me deshago de la burocracia que tiene la clase y confío más en el programador (chau verificación de rango, chau set/get inncecesarios): circular-r5Tested.py
Este es el hilo en la lista de PyAr: http://mx.grulic.org.ar/lurker/message/20070221.033607.fd125b8e.es.html
Algunas referencias
